GSoC 2017 - Coding Period | Week 1
You're here : Homepage > Blog > This Blog Post
Read this post Share Tweet 2-minutes readGSoC 2017 - Coding Period | Week 1
Posted on 04/06/2017 at 9:00 PM by The Vibe.

First week of Coding period of GSoC 2017 as per my timeline, started on the
29th of May 2017. This was something I was really looking up to, right from
the moment I was selected by SciRuby organization
( GitHub | Website )
for my project idea daru-io
. In my opinion, the first week was very
interesting and productive. Through this blog post, I'd like to document my
progress during this week.
HTML Importer for daru
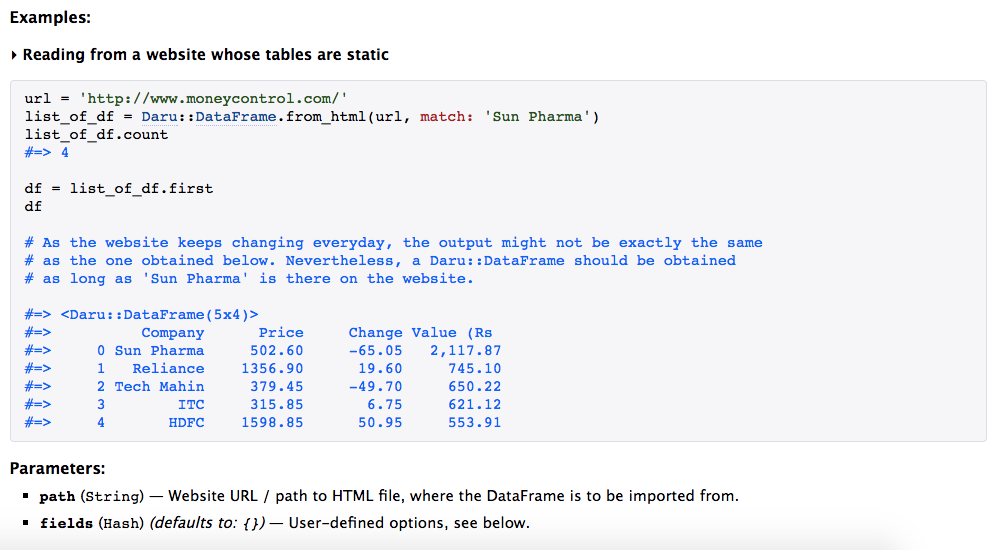
During the earlier part of this week, I continued on my Pull Request
regarding the HTML Importer method for daru , Daru::DataFrame.from_html()
.
Through this method, I implemented web scraping to get tables from a HTML
page and convert them to an Array
of Daru::DataFrame
s. The Mechanize
gem has been used to implement web scraping.
Though the method is now able to properly parse the dataframes from a couple of websites, it does have a downside. The downside is that, there are websites that dynamically load the HTML tables by inline JS, and this method won't be able to parse such tables.
The logic behind detection of index and order of a table can be seen from this Pull Request. Have a look at a couple of screenshots documenting the method with an example -

Setting up daru-io repository
Porting existing IO modules of daru to daru-io
The existing IO modules of daru - 5 importers and 2 exporters, are to be ported to the daru-io repository to ensure that subsequent IO modules that are to be newly formed, look consistent with the older ones. That way, daru-io can also be released as a plugin gem to daru, by August end. By Friday, I had ported the existing modules with updated YARD docs styling and modern syntax for RSpec tests. However, a review comment by mentor Victor (@zverok) seems to suggest a better inheritence layout and usage methodology to daru-io modules.
That is, something used like Daru::IO::Exporters::CSV.write('path/to/csv/file', options)
can now be used with lazy-calling feature such as,
csv_exporter = Daru::IO::Exporters::CSV.new('path/to/csv/file', options)
# Do some thing here
csv_exporter.write
This is still under progress with this Pull Request, and isn't merged yet. Once the lazy-calling feature has been approved for one module, it is easy to extend them to other modules. I've been putting effort from my side, and it hopefully doesn't delay my timeline. But if it does, I've a swiss-knife up my sleeve called 'Buffer period', which is meant for handling such delays.
Adding fixture files to daru-io
Fixture files are the input files that are used in testing the modules (importers, in my case). As I'd like to tackle various format importers such as Redis, Mongodb, JSON, Avro, RData & RDS in my GSoC tenure, it's a good starting point to start adding the fixture files. Progress regarding this has been made in this Pull Request, and is yet to be merged.